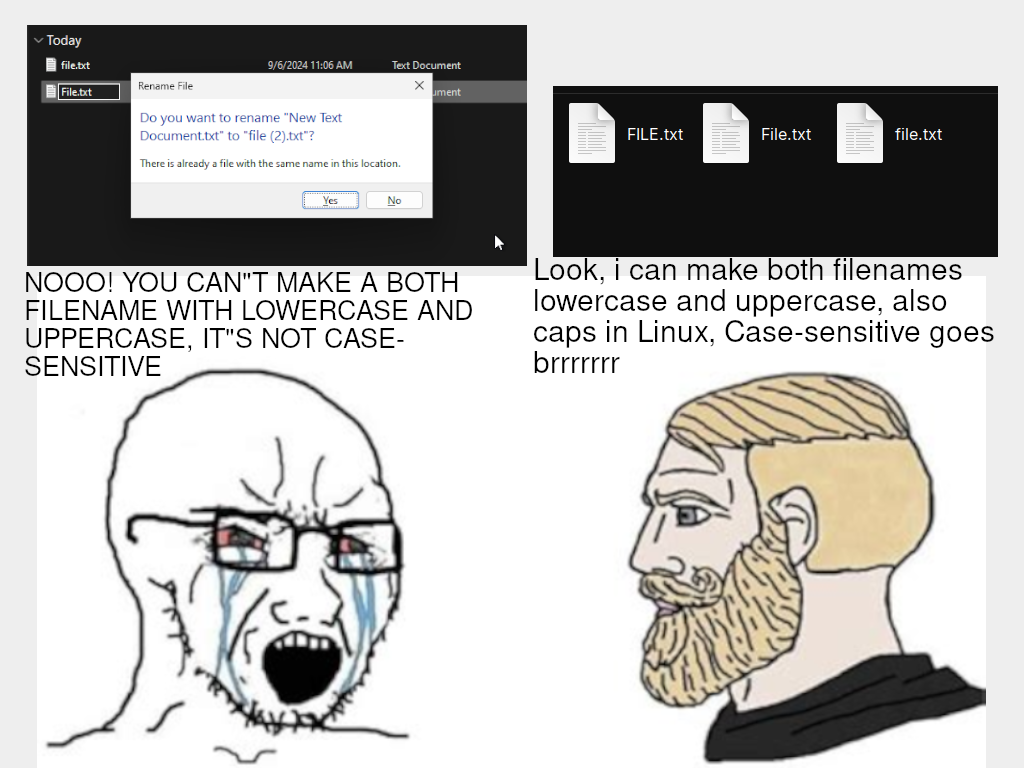
I don’t really see the benefit of allowing users to create files with the same name in the same directory, yeah, yeah I know that case sensitivity means that it isn’t same name, but imagine talking to a user, guiding them to open the file /tmp/doc/File and they open /tmp/doc/file instead
The reason, I suspect, is fundamentally because there’s no relationship between the uppercase and lowercase characters unless someone goes out of their way to create it. That requires that the filesystem contain knowledge of the alphabet, which might work if all you wanted was to handle ASCII in American English, but isn’t good for a system which needs to support the whole world.
In fact, the UNIX filesystem isn’t ASCII. It’s also not unicode. UNIX uses arbitrary byte strings, with special significance given to a very small number of bytes (just ‘/’ and ‘\0’, I think). That means people are free to label files in whatever way they like, and their terminals or other applications are free to render them in whatever way seems appropriate, without the filesystem having to understand unicode.
Adding case insensitivity would therefore actually be significant and unnecessary complexity to add to the filesystem drivers, and we’d probably take a big step backwards in support for other languages
Let’s say you have a software that generates randomly named files, having the ability to use both upper case and lower case means you can have more files with the same amount of characters, but that sounds horrible and it’s the only thing I can think of atm


{kind=link}
I don’t really see the benefit of allowing users to create files with the same name in the same directory, yeah, yeah I know that case sensitivity means that it isn’t same name, but imagine talking to a user, guiding them to open the file /tmp/doc/File and they open /tmp/doc/file instead
The reason, I suspect, is fundamentally because there’s no relationship between the uppercase and lowercase characters unless someone goes out of their way to create it. That requires that the filesystem contain knowledge of the alphabet, which might work if all you wanted was to handle ASCII in American English, but isn’t good for a system which needs to support the whole world.
In fact, the UNIX filesystem isn’t ASCII. It’s also not unicode. UNIX uses arbitrary byte strings, with special significance given to a very small number of bytes (just ‘/’ and ‘\0’, I think). That means people are free to label files in whatever way they like, and their terminals or other applications are free to render them in whatever way seems appropriate, without the filesystem having to understand unicode.
Adding case insensitivity would therefore actually be significant and unnecessary complexity to add to the filesystem drivers, and we’d probably take a big step backwards in support for other languages
Oh, I realize why it is, I just don’t see it as an advantage, the whole argument is just a technical one, not a usabillity one.
Let’s say you have a software that generates randomly named files, having the ability to use both upper case and lower case means you can have more files with the same amount of characters, but that sounds horrible and it’s the only thing I can think of atm