
Previous posts: https://programming.dev/post/3974121 and https://programming.dev/post/3974080
Original survey link: https://forms.gle/7Bu3Tyi5fufmY8Vc8
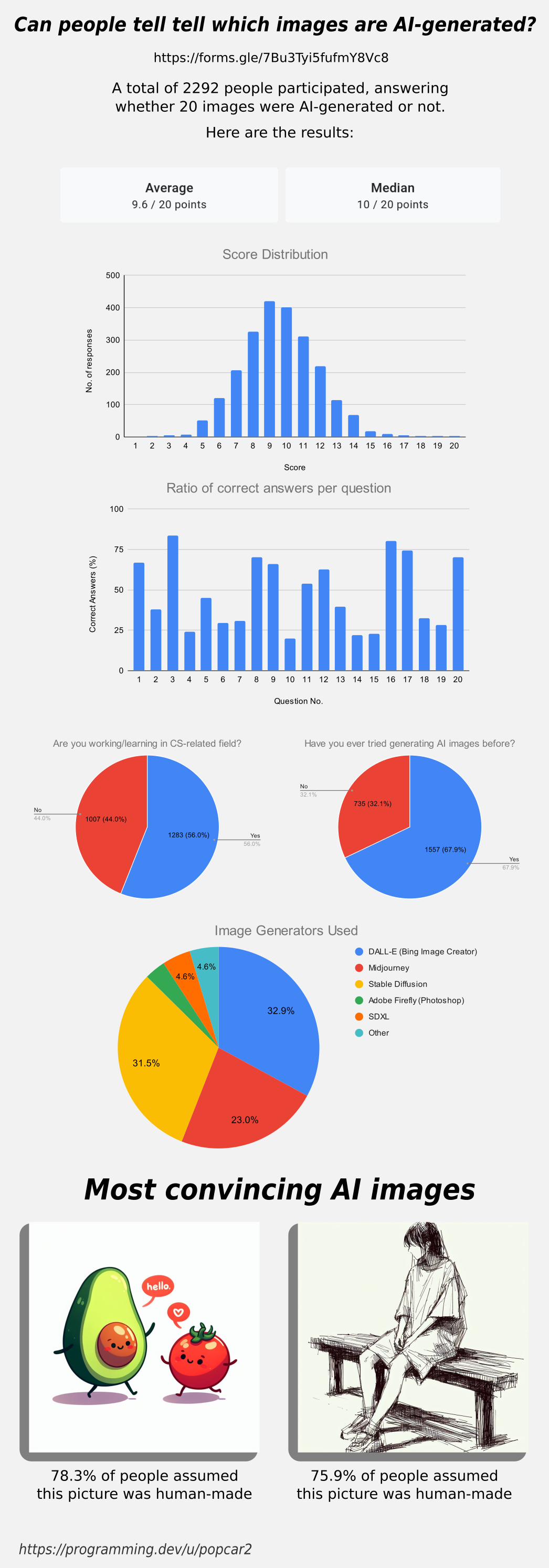
Thanks for all the answers, here are the results for the survey in case you were wondering how you did!
Edit: People working in CS or a related field have a 9.59 avg score while the people that aren’t have a 9.61 avg.
People that have used AI image generators before got a 9.70 avg, while people that haven’t have a 9.39 avg score.
Edit 2: The data has slightly changed! Over 1,000 people have submitted results since posting this image, check the dataset to see live results. Be aware that many people saw the image and comments before submitting, so they’ve gotten spoiled on some results, which may be leading to a higher average recently: https://docs.google.com/spreadsheets/d/1MkuZG2MiGj-77PGkuCAM3Btb1_Lb4TFEx8tTZKiOoYI
So if the average is roughly 10/20, that’s about the same as responding randomly each time, does that mean humans are completely unable to distinguish AI images?
In theory, yes. In practice, not necessarily.
I found that the images were not very representative of typical AI art styles I’ve seen in the wild. So not only would that render preexisting learned queues incorrect, it could actually turn them into obstacles to guessing correctly pushing the score down lower than random guessing (especially if the images in this test are not randomly chosen, but are instead actively chosen to dissimulate typical AI images).
I would also think it depends on what kinds of art you are familiar with. If you don’t know what normal pencil art looks like, how are ya supposed to recognize the AI version.
As an example, when I’m browsing certain, ah, nsfw art, I can recognize the AI ones no issue.
Personally, I’m not surprised. I thought a 3D dancing baby was real.
It depends on if these were hand picked as the most convincing. If they were, this can’t be used a representative sample.
But you will always hand pick generated images. It’s not like you hit the generate button once and call it a day, you hit it dozens of times tweaking it until you get what you want. This is a perfectly representative sample.
As a personal example, this is what I generated and after like few hours of tweaking, regenerating and inpainting, this was the final result. And here’s another: initial generation, the progress animation, and end result.
Are they perfect, no, but the really obvious bad AI art comes from people who expect it to spit perfect images at you.
If you look at the ratios of each picture, you’ll notice that there are roughly two categories: hard and easy pictures. Based on information like this, OP could fine tune a more comprehensive questionnaire to include some photos that are clearly in between. I think it would be interesting to use this data to figure out what could make a picture easy or hard to identify correctly.
My guess is that a picture is easy if it has fingers or logical structures such as text, railways, buildings etc. while illustrations and drawings could be harder to identify correctly. Also, some natural structures such as coral, leaves and rocks could be difficult to identify correctly. When an AI makes mistakes in those areas, humans won’t notice them very easily.
The number of easy and hard pictures was roughly equal, which brings the mean and median values close to 10/20. If you want to bring that value up or down, just change the number of hard to identify pictures.
And this is why AI detector software is probably impossible.
Just about everything we make computers do is something we’re also capable of; slower, yes, and probably less accurately or with some other downside, but we can do it. We at least know how. We can’t program software or train neutral networks to do something that we have no idea how to do.
If this problem is ever solved, it’s probably going to require a whole new form of software engineering.
Wow, what a result. Slight right skew but almost normally distributed around the exact expected value for pure guessing.
Assuming there were 10 examples in each class anyway.
It would be really cool to follow up by giving some sort of training on how to tell, if indeed such training exists, then retest to see if people get better.
One thing I’d be interested in is getting a self assessment from each person regarding how good they believe themselves to have been at picking out the fakes.
I already see online comments constantly claiming that they can “totally tell” when an image is AI or a comment was chatGPT, but I suspect that confirmation bias plays a big part than most people suspect in how much they trust a source (the classic “if I agree with it, it’s true, if I don’t, then it’s a bot/shill/idiot”)
With the majority being in CS fields and having used ai image generation before they likely would be better at picking out than the average person
No shot the bottom left was ai gen without human help. AI has so much trouble delivering words and text.
Yes shot. Check out DALL-E 3.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}