
- neural network is trained with deep Q-learning in its own training environment
- controls the game with twinject
demonstration video of the neural network playing Touhou (Imperishable Night):
it actually makes progress up to the stage boss which is fairly impressive. it performs okay in its training environment but performs poorly in an existing bullet hell game and makes a lot of mistakes.
let me know your thoughts and any questions you have!
This is quite cool. I always find it interesting to see how optimization algorithms play games and to see how their habits can change how we would approach the game.
I notice that the AI does some unnatural moves. Humans would usually try to find the safest area on the screen and leave generous amounts of space in their dodges, whereas the AI here seems happy to make minimal motions and cut dodges as closely as possible.
I also wonder if the AI has any concept of time or ability to predict the future. If not, I imagine it could get cornered easily if it dodges into an area where all of its escape routes are about to get closed off.
I always find it interesting to see how optimization algorithms play games and to see how their habits can change how we would approach the game.
me too! there aren’t many attempts at machine learning in this type of game so I wasn’t really sure what to expect.
Humans would usually try to find the safest area on the screen and leave generous amounts of space in their dodges, whereas the AI here seems happy to make minimal motions and cut dodges as closely as possible.
yeah, the NN did this as well in the training environment. most likely it just doesn’t understand these tactics as well as it could so it’s less aware of (and therefore more comfortable) to make smaller, more riskier dodges.
I also wonder if the AI has any concept of time or ability to predict the future.
this was one of its main weaknesses. the timespan of the input and output data are both 0.1 seconds - meaning it sees 0.1 seconds into the past to perform moves for 0.1 seconds into the future - and that amount of time is only really suitable for quick, last-minute dodges, not complex sequences of moves to dodge several bullets at a time.
If not, I imagine it could get cornered easily if it dodges into an area where all of its escape routes are about to get closed off.
the method used to input data meant it couldn’t see the bounds of the game window so it does frequently corner itself. I am working on a different method that prevents this issue, luckily.
So the training environment was not Touhou? So what does the training environment look like? I’d be interested to see that, and how it improved over time.
yeah, the training environment was a basic bullet hell “game” (really just bullets being fired at the player and at random directions) to teach the neural network basic bullet dodging skills

- the white dot with 2 surrounding squares is the player and the red dots are bullets
- the data input from the environment is at the top-left and the confidence levels for each key (green = pressed) are at the bottom-left
- the scoring system is basically the total of all bullet distances
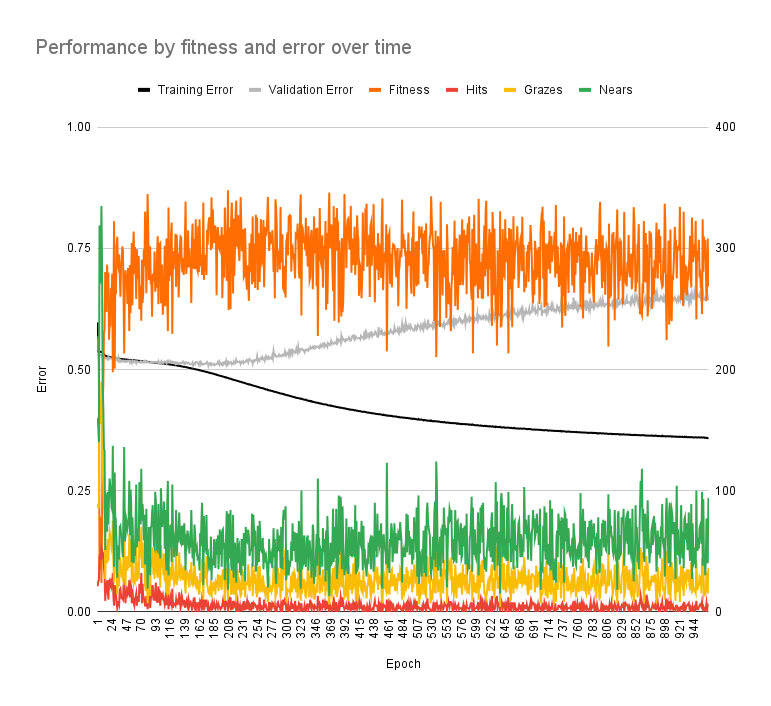
- this was one of the training sessions
- the fitness does improve but stops improving pretty quickly
- the increase in validation error (while training error decreased) is indicated overfitting
- it’s kinda hard to explain here but basically the neural network performs well with the training data it is trained with but doesn’t perform well with training data it isn’t (which it should also be good at)
That’s an interesting approach. The Traditional way would be to go by game score like the AI Mario Projects. But I can see the value in prioritizing Bullet Avoidance over pure score.
Does your training Environment Model that shooting at enemies (eventually) makes them stop spitting out bullets? I also would assume that total survival time is a part of the score, otherwise the Boss would just be a loosing game score wise.
the training environment is pretty basic right now so all bullets shoot from the top of the screen with no enemy to destroy.
additionally, the program I’m using to get player and bullet data (twinject) doesn’t support enemy detection so the neural network wouldn’t be able to see enemies in an existing bullet hell game. the character used has a wide bullet spread and honing bullets so the neural network inadvertently destroys the enemies on screen.
the time spent in each training session is constant rather than dependent on survival time because the scoring system is based on the total bullet distance only.
A bit offtopic but either way, have you ever tried applying NN agents on games with incomplete information, card games with opponents and alike?
I did create a music NN and started coding an UNO NN, but apart from that, no
Wouldn’t a regular bot be easier to make and perform better?
currently, yes, but this is more an investigation into how well a neural network could play a bullet hell game
very few bullet hell AI programs rely on machine learning and virtually all of the popular ones use algorithms.
but it is interesting to see how it mimics human behaviour, skills and strategies and how different methods of machine learning perform and why
(plus I understand machine learning more than the theory behind those bullet hell bots.)

